Small Language Models–Think Big. Act Small.

Summary: While Large Language Models grab the spotlight, a quieter revolution is emerging – Small Language Models that pack a big punch in a lean build.
Does bigger mean better?
The AI playbook is slowly but gradually shifting.
Leading tech players are building leaner, faster versions of their flagship models designed for real-world deployment – offering everything from heavy reasoning to rapid, low-cost inference. Even start-ups are demonstrating that smaller models can deliver performance close to that of top-tier systems, using fewer parameters.
Does it matter? Absolutely!
Because smaller models are built for speed and practicality. They train faster, deploy cheaper, and respond quicker. And for teams looking to integrate AI without the massive infrastructure overhead, this significantly lowers the barrier.
There’s also a sustainability upside. Leaner models demand less compute, which translates directly into lower energy consumption—an increasingly critical factor as AI adoption scales.
But perhaps the biggest shift is where these models can run.
Instead of relying entirely on the cloud, compact models can now operate on-device- inside phones, apps, and edge systems—bringing intelligence closer to the user, with lower latency and greater control.
The takeaway is clear.
Small is no longer a compromise. It’s a strategy. And the future of AI isn’t just about power and precision- it is also about portability and efficiency.
Small Language Models (SLMs) - When small is powerful
A Small Language Model is the streamlined, resource-efficient Natural Language Processing Model (NLP) alternative to the expansive Large Language Model (LLM) with minimal parameters.
While LLMs like GPT-4o are built with hundreds of billions or even trillions of parameters, SLMs operate with far fewer (typically under 10 billion), enabling them to handle targeted tasks trained on smaller datasets with minimal computational demands and energy usage. An indispensable component in the intelligence market, SLMs have contributed effectively towards the democratization of AI.
SLMs at a Glance
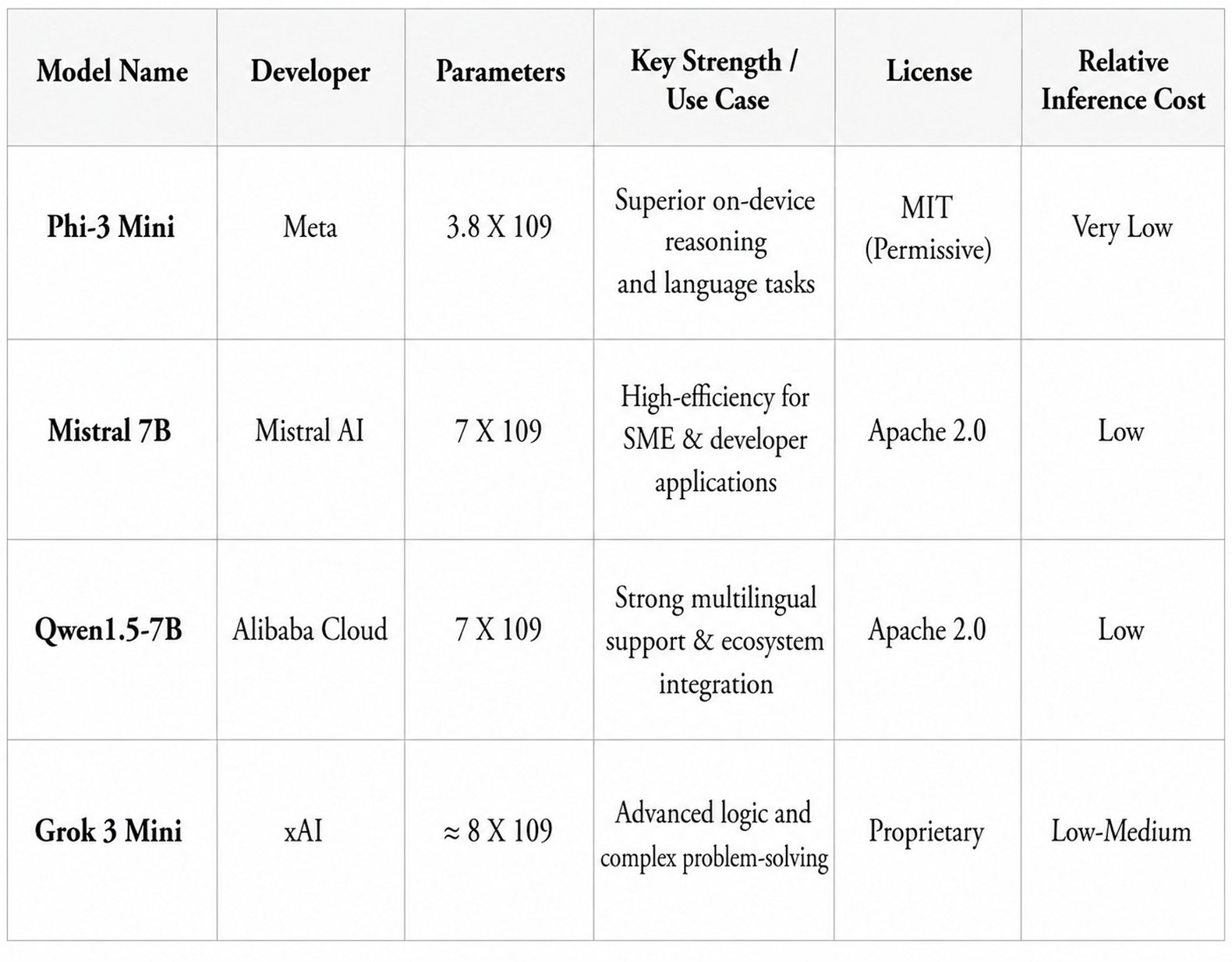
(Image Courtesy: ainewshub)
How SLMs Work


SLMs- Techniques & Approaches
Distillation
Distillation transfers knowledge from a large “teacher” model to a smaller “student” model, compressing their capabilities without major accuracy loss.
Examples
- DistilBERT – a 40% smaller and 60% faster version of BERT created via knowledge distillation.
- GPT-4o mini – distilled from GPT-4o for efficient performance.
Pruning
Pruning reduces model size even as it preserves accuracy and performance for efficient SLM deployment.
Example
In financial applications, pruning can target an SLM for fraud detection by eliminating redundant pathways learned during training. This helps it run faster and allows real-time fraud checks directly on local (edge) devices, without relying on external servers.
Quantization
Quantization uses fewer bits to store the model’s numbers.
Example
In investment management, a quantized SLM can easily analyze bank statements on mobile devices, processing transaction data faster for portfolio risk alerts compared to full LLMs.
Efficient Fine-Tuning for SLMs
Low-Rank Adaptation (LoRA) for Efficient Fine-Tuning
LoRA fine-tunes SLMs by injecting trainable low-rank matrices into transformer layers, significantly reducing the number of trainable parameters while maintaining performance.
QLoRA for Memory-Optimized Training
Quantized LoRA (QLoRA) techniques enable high-quality fine-tuning using 4-bit quantization to lower GPU memory requirements and facilitate large-scale adaptation feasible on cost-efficient hardware.
Parameter-Efficient Training (PET) Methods
Parameter-Efficient Tuning (PET) methods, such as adapters, prefix tuning, prompt tuning, and LoRA variants, enable faster training cycles while significantly reducing computational demands and storage requirements.
Selective Layer Fine-Tuning Strategies
This technique involves training that focuses only on critical layers or attention modules instead of full-model retraining to optimize resource utilization and reduce training time.

Choosing Between LLMs and SLMs
Choosing between small and large language models isn’t about one being universally superior—it’s about finding the one that best fits your particular requirements. This, in turn, depends on task complexity, resource availability, and deployment environment.
For instance, a hospital may use an LLM on central servers for complex medical research, while deploying an SLM on portable devices to enable real-time patient monitoring and quick clinical decision support.
SLMs- Challenges
Training Data Procurement and Quality Constraints
Acquiring high-quality, domain-specific datasets remains a major challenge due to data privacy restrictions, licensing concerns, fragmented data sources, and inconsistent labeling quality.
Bias, Noise, and Data Imbalance
Managing noisy annotations, skewed distributions, and under-represented scenarios is critical to ensure reliable and fair model behavior.
Compute and Infrastructure Limitations
Even with PET methods, training and experimentation can face GPU memory constraints, storage bottlenecks, and rising infrastructure costs.
Inference Efficiency for SLMs
Optimizing inferencing for low latency and high throughput across edge devices or enterprise environments requires careful balancing of model size, quantization levels, and response quality.
Context Window and Knowledge Retention Limitations
Smaller models may struggle with long-context reasoning, multi-hop understanding, or retaining domain knowledge without external retrieval support.
Evaluation and Benchmarking Complexity
Measuring real-world performance across accuracy, hallucination rates, latency, and cost efficiency requires comprehensive benchmarking frameworks beyond standard NLP metrics.
Security, Privacy, and Compliance Risks
Training on sensitive enterprise or regulated datasets necessitates strong governance frameworks, anonymization strategies, and secure deployment architectures.
SLMs or LLMs? A Heterogeneous Way Forward
By strategically blending the advanced capabilities of LLMs with the efficiency and agility of SLMs, organizations can tailor AI solutions that align precisely with their operational demands and infrastructure limitations, unlocking maximum value and competitive advantage.
The most capable agentic systems, in fact, rely on a blend of different architectures, such as:
- Small language models (SLMs) to manage repetitive or straightforward tasks like API interactions, data transformation, and basic reasoning steps.
- Large language models (LLMs) to oversee complex responsibilities, including strategic planning, tackling open-ended challenges, and coordinating broad workflows.
- Router models that intelligently assign tasks by selecting the optimal model for each operation.
Though SLMs may not understand as deeply or flexibly as their larger counterparts, their focused expertise and speed make them ideal for many practical applications requiring quick, reliable language understanding.