- Introduction to Vector Database
- From Words to Numbers- How Vector Database Understands Meaning
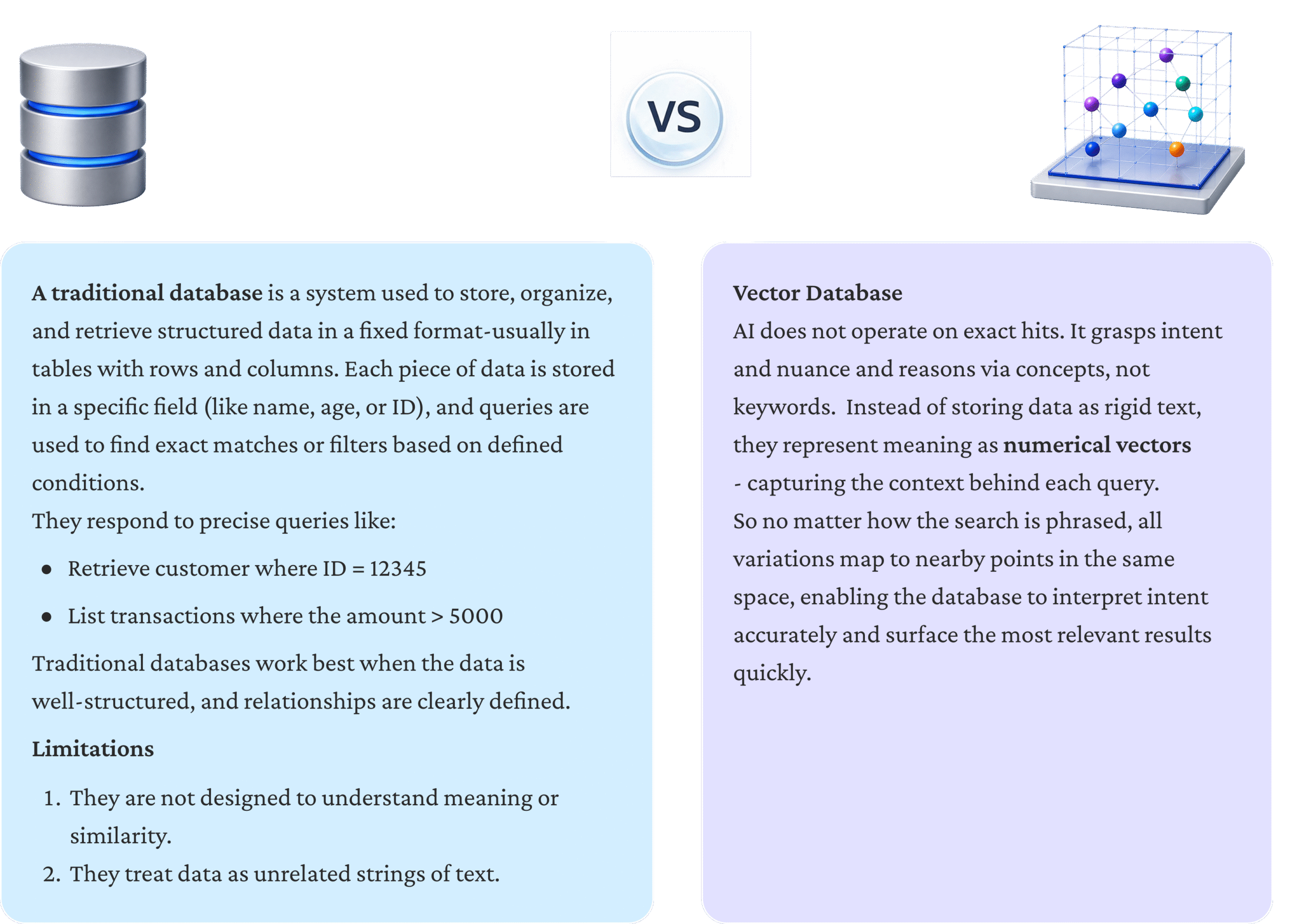
- Traditional vs. Vector Database
- Vector Database - A paradigm shift from keywords to context
- Inside a Vector Database: What Actually Happens
- Vector Database- More than an upgrade – a strategic reset
- The Future of Intelligent Search
VECTOR DATABASE -
GO FROM SEARCH TO SUPER-INTELLIGENCE

Data used to be easy to query—because it was structured. Everything lived in rows, columns, and well-defined schemas. Retrieval was exact, deterministic, and fast. But as data evolved, that model began to strain. And working with increasingly unstructured, high-dimensional, and context -rich data – spanning text, images, audio, and user behaviour, raised a new challenge: interpretation.
Vector Database –The foundation of context-driven AI systems
In a landscape where relevance outweighs exactness, vector databases are engineered to redefine how we search, discover, and interact with unstructured information.
At their core, they mark a dynamic shift: from retrieval to understanding—encoding data as numbers that capture context, similarity, and intent.
Vector databases are particularly useful for similarity searches, enabling applications like enterprise knowledge bases, chatbots, virtual assistants, recommendation systems, personalized searches, and anomaly detection.
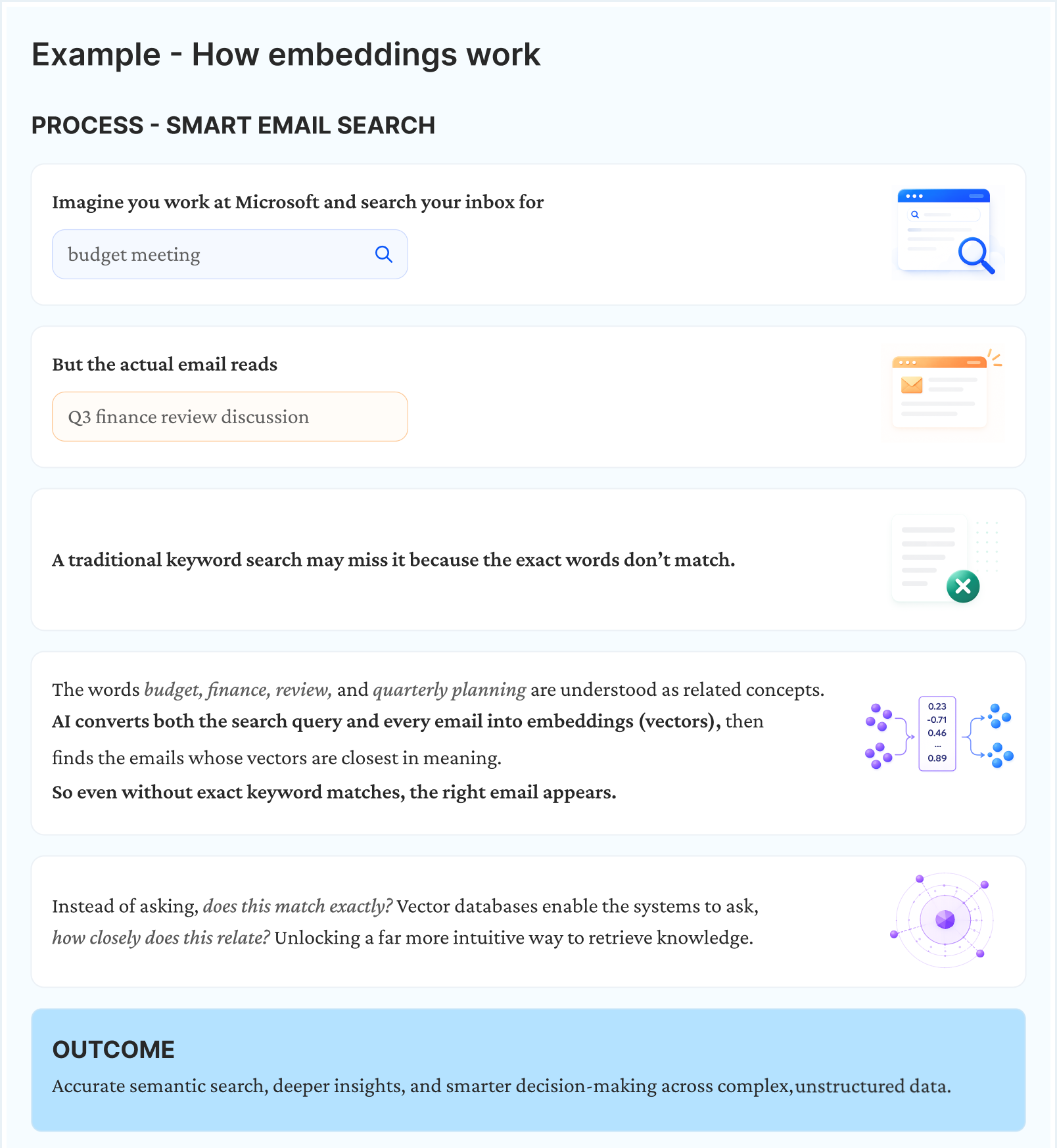
From Words to Numbers- How Vector Database Understands Meaning
A vector database stores and searches high-dimensional vector embeddings.
Embeddings are numerical representations of data – text, images, audio – that capture the contextual meaning of data in a machine-readable form. Analyzing patterns, dependencies, and associations within the data, they place semantically similar items close together and dissimilar ones far apart.
Traditional vs. Vector Database
Vector Database - A paradigm shift from keywords to context
Consider these searches:
Top AI coding assistant for developers.
Best developer tool for faster debugging.
Smart platform that boosts engineering productivity.
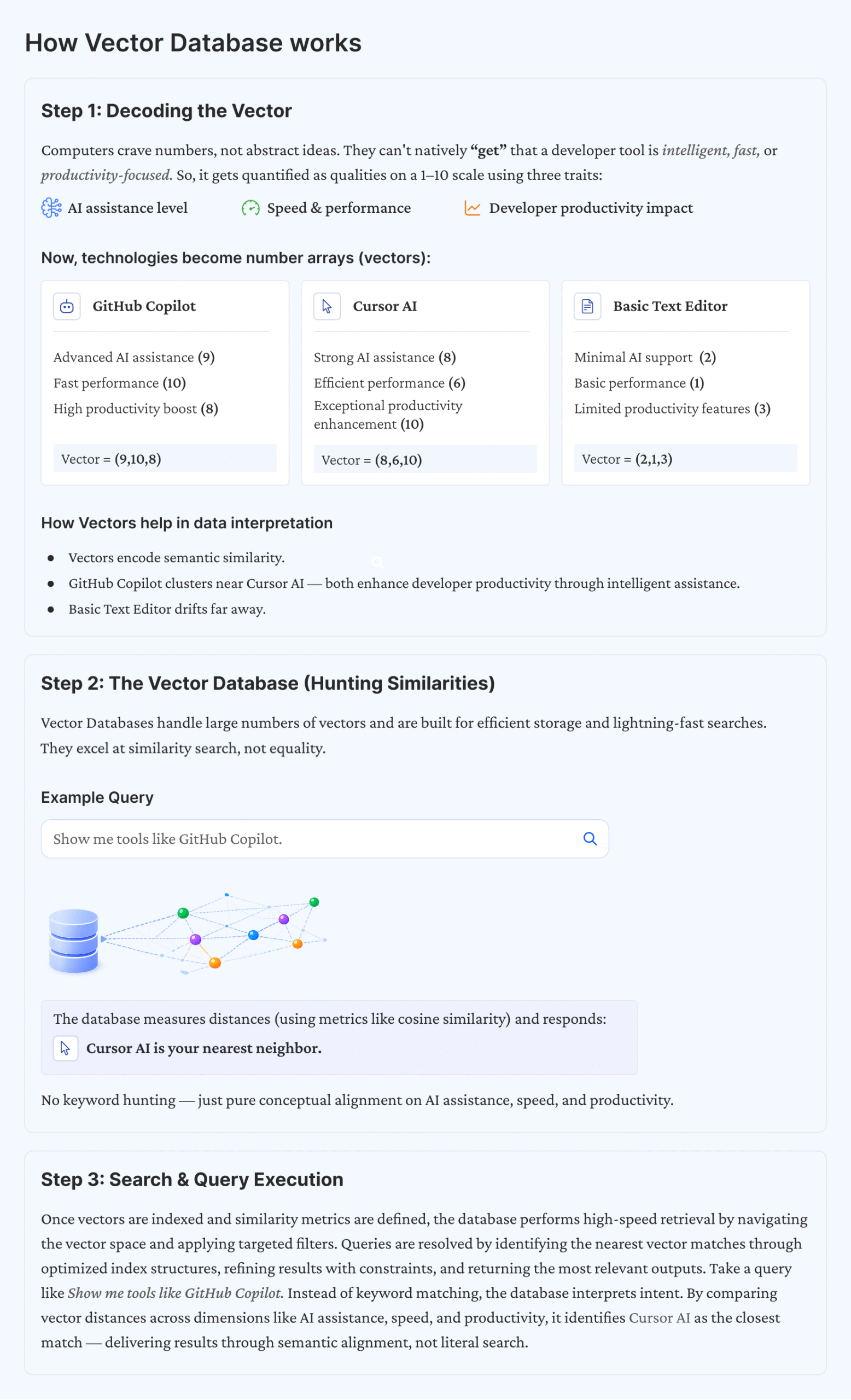
Inside a Vector Database: What Actually Happens
Every high-performing AI system using vectors runs through a tight, three-stage loop.
1. Indexing — Turning Chaos into Structure
Without speed, embeddings are just stored potential.
This stage takes high-dimensional vectors and maps them into optimized data structures using techniques like:
- Hierarchical Navigable Small World (HNSW) – Graph-based, ultra-fast retrieval.
- Locality-Sensitive Hashing (LSH) – Probabilistic grouping for quick similarity buckets.
- Product Quantization (PQ) – Compressed representations to scale efficiently.
Done right, indexing is what separates millisecond responses from system lag.
2. Querying — Realtime Similarity Search
When a query comes in, it’s converted into a vector and pushed through the index.
The system doesn’t “search” in the traditional sense—it computes proximity using metrics that include:
- Cosine similarity
- Dot product
- Euclidean distance
Instead of scanning everything, it jumps straight to the most relevant cluster and pulls the closest matches.
It is like, “Don’t look everywhere—go exactly where the answer is likely to be.”
3. Post-Processing — Refining the Answer
Raw and the nearest neighbors aren’t always the best final answer.
This layer cleans things up before results hit your application:
- Re-ranking results using a more precise (but slower) model
- Applying filters (time, metadata, permissions)
- Blending signals (relevance + business logic)
And this is where systems move from technically correct to contextually right.
Why This Pipeline Matters
Each of these stages solves a different bottleneck-
Indexing → scale
Querying → speed
Post-processing → quality
Miss one, and your system breaks →
great models + poor indexing = slow product
fast retrieval + no re-ranking = irrelevant results
good pipeline + bad tuning = wasted compute
The Takeaway
If you’re building AI products, your advantage doesn’t come from just using vectors.
It comes from how well you optimize each stage of this pipeline for your use case.
Vector Database- More than an upgrade – a strategic reset
For modern AI systems, speed and precision aren’t trade-offs—they’re expectations. Vector databases are engineered to deliver both at scale.
Blazing-fast search
Advanced indexing techniques power near-instant similarity matching—even across massive datasets—so insights keep up with decision-making.
Always-on reliability
Distributed architecture with built-in redundancy ensures continuous availability, even when components fail.
Granular security control
Fine-tuned access frameworks keep data protected, with permissions aligned to roles, attributes, and organizational policies.
Seamless multi-tenancy
Multiple teams, products, or clients can operate in parallel—securely isolated, yet efficiently managed within a single system.
Effortless scalability
Expands capacity on demand by adding nodes, increasing throughput, and handling growing workloads without disruption.
Performance tuning on demand
Optimizes for your priorities—speed, accuracy, or cost—through flexible configuration and resource control.
Developer-first integration
Robust APIs and SDKs make it easy to plug into applications, enabling rapid development and deployment of AI-powered features.
The Future of Intelligent Search
Vector databases aren’t just another infrastructure choice; they’re quickly becoming the backbone of how modern AI products think, search, and respond in real time. And if your system needs to find the right match instantly, this is the layer that makes it happen.
It scales with your ambition, integrates with your ecosystem, and performs where it matters most.
So, move from searching to knowing. Because every millisecond and every insight matters.